Jina AI Reader, a powerful tool developed by Jina AI, transforms any URL into LLM-friendly Markdown content, enhancing the efficiency of AI agents and RAG systems by providing structured, high-quality data input for tasks such as summarization and question answering. With its versatile capabilities, including support for PDFs and advanced customization options, Jina Reader is set to revolutionize content extraction for AI applications.
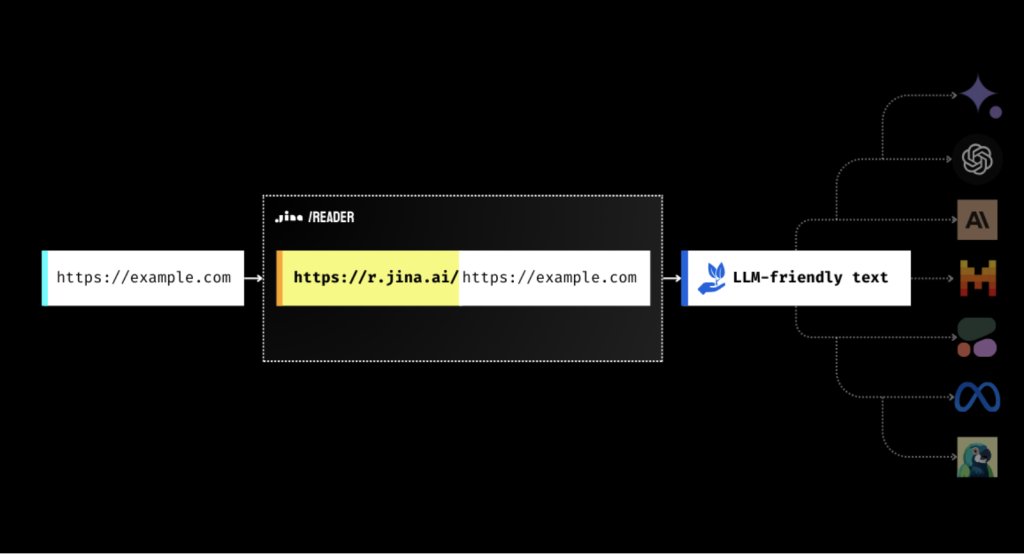
Jina AI Reader, a powerful tool developed by Jina AI, transforms any URL into LLM-friendly Markdown content, enhancing the efficiency of AI agents and RAG systems by providing structured, high-quality data input for tasks such as summarization and question answering.

Integrating Jina Reader into projects is straightforward and can significantly enhance AI applications. Developers can access the Reader API by simply adding the prefix “https://r.jina.ai/” to any URL, which returns the content in a Markdown format optimized for LLMs. The service is free to use with a rate limit of 20 requests per minute, which can be increased to 200 requests per minute with a free API key. For more advanced usage, Jina AI provides SDKs in Python and JavaScript, allowing seamless integration into existing codebases. The Reader’s ability to handle various content types, including PDFs, makes it versatile for diverse applications in natural language processing and information retrieval.
Jina Reader has expanded its capabilities to include native support for PDF files, enhancing its versatility in content extraction. Users can easily process PDF documents by prepending “https://r.jina.ai/” to the PDF’s URL, just as they would with web pages. This feature is particularly useful for accessing academic papers, such as those on arXiv, where users can choose between processing the PDF directly or using the HTML version of the document. The PDF reading functionality is designed to be compatible with most PDFs, including those containing numerous images, and boasts high-speed performance. This addition significantly broadens the range of content types that can be efficiently converted into LLM-friendly formats, making Jina Reader an even more powerful tool for researchers and developers working with diverse document sources.
Jina AI Reader offers advanced customization options for output formats, enhancing its versatility for various use cases. Users can specify their preferred format, including HTML, plain text, Markdown, or even screenshots of the webpage. This flexibility allows developers to tailor the output to their specific needs, whether for direct LLM input or further processing. Additionally, the Reader API supports a “Wait For Selector” feature, which is particularly useful when dealing with dynamically loaded content that may not be immediately available upon page load. For more complex scenarios, Jina AI provides a search endpoint (s.jina.ai) that enables web searches and retrieves the top 5 results, facilitating search grounding for LLMs with up-to-date information. These advanced features make Jina Reader a powerful tool for developers seeking to optimize their AI workflows and improve the quality of input data for language models.
Jina AI Reader significantly enhances AI applications by addressing a critical challenge in natural language processing: the quality of input data. By converting messy, unstructured web content into clean, structured Markdown format, it provides high-quality, LLM-friendly inputs that are crucial for improving the performance of AI agents and Retrieval-Augmented Generation (RAG) systems. This preprocessing step is particularly beneficial for tasks such as summarization, question answering, and insight generation, as it ensures that language models receive well-formatted, relevant information. The Reader’s ability to handle various content types, including PDFs and dynamically loaded web pages, expands its utility across diverse applications, from academic research to real-time web content analysis. By streamlining the data extraction and formatting process, Jina AI Reader enables developers to focus on building more sophisticated AI solutions while reducing the time and effort spent on data preparation and cleaning.
The Reader API significantly enhances LLM performance by addressing the critical “garbage in, garbage out” principle in AI. By converting messy, unstructured web content into clean, LLM-friendly formats, it ensures that language models receive high-quality input data. This preprocessing step is particularly beneficial for less advanced LLMs that may struggle with understanding unstructured or complex data formats. The Reader API’s ability to extract core content from URLs and convert it into clean text improves the accuracy and relevance of LLM outputs for tasks such as summarization, question answering, and insight generation. Additionally, its image captioning feature enriches the context provided to LLMs, enabling more comprehensive understanding and analysis of web content. By streamlining the data acquisition and structuring process, the Reader API allows developers to focus on building more sophisticated AI applications while ensuring optimal LLM performance across various use cases.
The Reader API employs advanced techniques to handle dynamic content on websites effectively. It uses a proxy to fetch URLs and renders the content in a browser environment, allowing it to capture dynamically loaded elements that may not be immediately available upon initial page load. For particularly complex or dynamic pages, the API includes a “Wait For Selector” feature, which delays content extraction until specified elements are fully rendered. This ensures that even JavaScript-heavy websites with asynchronously loaded content are accurately processed. The Reader API generally processes URLs and returns content within 2 seconds, though more complex pages may require additional time. This approach enables the API to provide a more comprehensive and accurate representation of web content, including elements that traditional web scraping methods might miss, making it especially valuable for processing modern, interactive websites.